ZWISCHEN ALERT UND EINGRIFF BLEIBT OFT EINE OPERATIVE LÜCKE.
Ihre Systeme melden Probleme, greifen aber nicht selbst ein. Vaiking schließt diese Lücke mit definierten, freigegebenen Aktionen, bevor manuelles Handeln nötig wird.
Voraussetzung: laufendes Vaiking Monitoring. Das Automatisierungs-Modul setzt einen validierten Datenstrom voraus. Das Monitoring muss stabil sein, bevor Automatisierung sinnvoll ist.
EINGRIFFE PASSIEREN. ABER NIEMAND KANN BELEGEN, OB SIE GEWIRKT HABEN.
Eine Aktion läuft um 03:00 Uhr durch. Das System meldet: ausgeführt. Aber hat es das Problem behoben? Ist der Zustand jetzt stabil? Oder läuft dieselbe Ursache weiter und erzeugt in einer Stunde die nächste Eskalation?
Automatisierung ohne Erfolgskontrolle bleibt operativ unvollständig. Und in kritischer Infrastruktur ist „ausgeführt" keine ausreichende Antwort.
SLA GESCHÜTZT. NUR RELEVANTE ESKALATIONEN. JEDER EINGRIFF BELEGBAR.
SLA-Schutz ohne manuelle Überwachung
Eingriffe werden ausgeführt und bestätigt, bevor der nächste Schwellenwert gerissen wird. Kein manuelles Nachschauen, ob die Aktion gewirkt hat.
Bereitschaft als Fallback, nicht als Standard
Die Bereitschaft wird nur dann eskaliert, wenn eine automatisierte Maßnahme nicht zum Zielzustand geführt hat. Nicht nach jeder automatisierten Ausführung.
Jeder Eingriff belegbar
Wann eingegriffen wurde, mit welchem PRE-Status, welchem Ergebnis, ob Fallback ausgelöst wurde: vollständig protokolliert, ohne manuelle Dokumentation.
JEDER EINGRIFF MIT MESSBAREM ERGEBNIS. ODER SOFORTIGER ESKALATION.
Andere Systeme führen aus und schweigen. Vaiking misst den Zustand danach und reagiert, wenn das Ergebnis vom Soll abweicht.¹
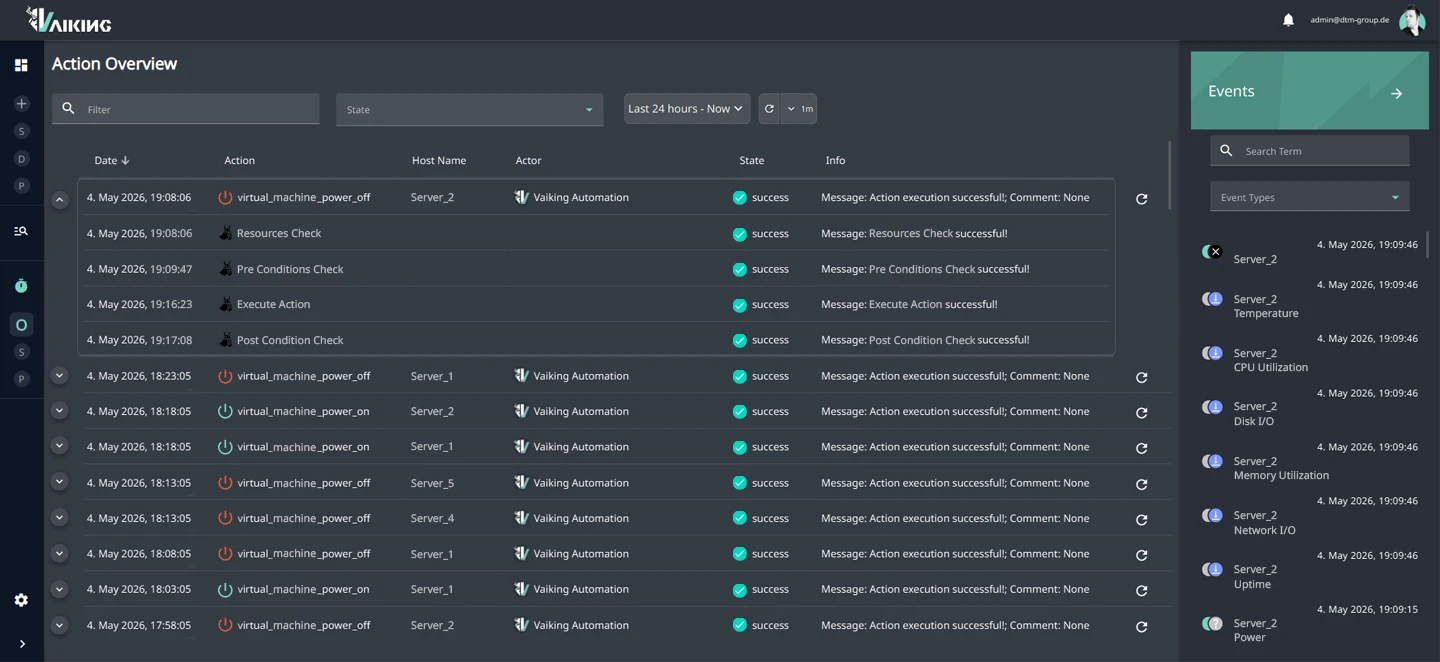
PRE: Vorbedingungen prüfen Bevor Vaiking eingreift, laufen zwei parallele Prüfungen. Pre-Conditions prüfen Zustände: Ist das Ziel erreichbar? Kein aktives Wartungsfenster? Kein paralleler Eingriff auf demselben Segment? Ressourcenpools prüfen Kapazitäten: Ist das konfigurierte Budget für Netzstrom, parallele Aktionen oder andere definierte Ressourcen noch verfügbar? Schlägt eine der Prüfungen fehl, startet die Aktion nicht. Das System eskaliert stattdessen.
EXEC: Aktion ausführen Dienst-Neustart, Reboot, VM-Migration, Konfigurationsänderung, usw. Die Aktion läuft über Protokolle wie REST-API, SSH oder SNMP auf dem Zielsystem.
POST: Zustand messen Nach der Aktion misst Vaiking den Ist-Zustand gegen das konfigurierte Ziel: Dienstverfügbarkeit, Temperatur oder Replikationsstatus. Wird das Ziel nicht erreicht, führt das System die konfigurierten Folgeaktionen aus oder eskaliert direkt. Kein Eingriff bleibt ohne Rückmeldung.
Fallback & Kompensation Schlägt der POST-Check fehl, reagiert das System sofort: konfigurierte Folgeaktion oder Eskalation an die Bereitschaft. Welche Reaktion greift, ist pro Aktion definiert. In keinem Fall bleibt ein fehlgeschlagener Eingriff unregistriert.
Kontrollschicht Zusätzlich zur PRE/POST-Logik schützt eine Kontrollschicht gegen unkontrollierte Ausführung: Cooldowns verhindern Flapping, Downtime-Checks blockieren Aktionen in Wartungsfenstern, Ressourcenpools begrenzen parallele Eingriffe.
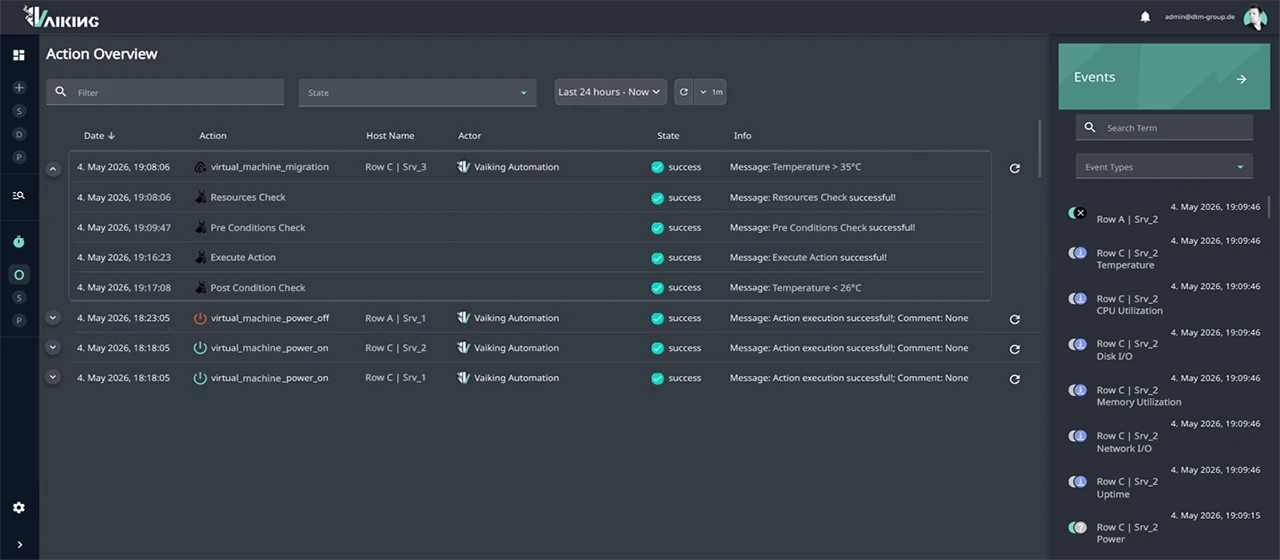
Trigger-Quellen
Zeitgesteuert, Zustandsänderungen, Schwellenwertüberschreitungen, aggregierte Werte, KI-Ergebnisse und manuelle Auslösung. Sechs Triggertypen, kombinierbar ohne Codeentwicklung.
Aktions-Typen
Vaiking greift über Protokolle wie REST-API, SSH und SNMP auf Zielsysteme zu. Die dafür nötigen Zugangsdaten werden im zentralen Credential-Store verschlüsselt hinterlegt und zur Laufzeit bezogen. Kein Klartext in Konfigurationsdateien. Typische Aktionen: Dienst-Neustart, Reboot, Interface-Konfiguration nach Patch-Ausführung, Konfigurationsänderung. Aktionen können einzeln oder im Batch auf mehrere Zielsysteme angewendet werden. Alle Aktionen laufen durch die PRE/POST-Prüflogik.
¹ Pre-/Post-Condition-Checks bei automatischen Aktionen: durch Gebrauchsmuster geschützt.
KANN ICH DAS VERANTWORTEN, WENN ETWAS SCHIEFGEHT?
Fehlaktionen können rückgängig gemacht werden
Schlägt der POST-Check fehl, führt das System die konfigurierten Folgeaktionen aus, ohne Betriebsunterbrechung. Welche Reaktion greift, ist pro Aktion definiert. Kein fehlgeschlagener Eingriff bleibt unregistriert.
Vollständig dokumentiert
Jede Aktion wird lückenlos protokolliert: PRE-Bedingungen mit Einzelergebnis, Ausführungszeitpunkt, POST-Messung und, bei Abweichung, ausgelöste Folgeaktion oder Eskalation.
Kein Eingriff ohne validierten Datenstrom
Trigger, Prüflogik und Aktionen greifen auf denselben Datenstrom zu wie das Monitoring. Keine Latenz zwischen Erkennung und Reaktion, keine Synchronisationsprobleme.
Zugangsdaten zentral verwaltet, nicht exponiert
Vaiking führt Aktionen über Protokolle wie SSH, SNMP und REST-API aus. Das setzt Zugang zu Ihren Systemen voraus. Zugangsdaten werden zentral im System verschlüsselt hinterlegt und zur Laufzeit bezogen. Kein Klartext in Konfigurationsdateien, kein geteilter Passwort-Store.
THERMISCHE ANOMALIE: KEIN MANUELLER EINGRIFF, KEIN SLA-VERSTOSS
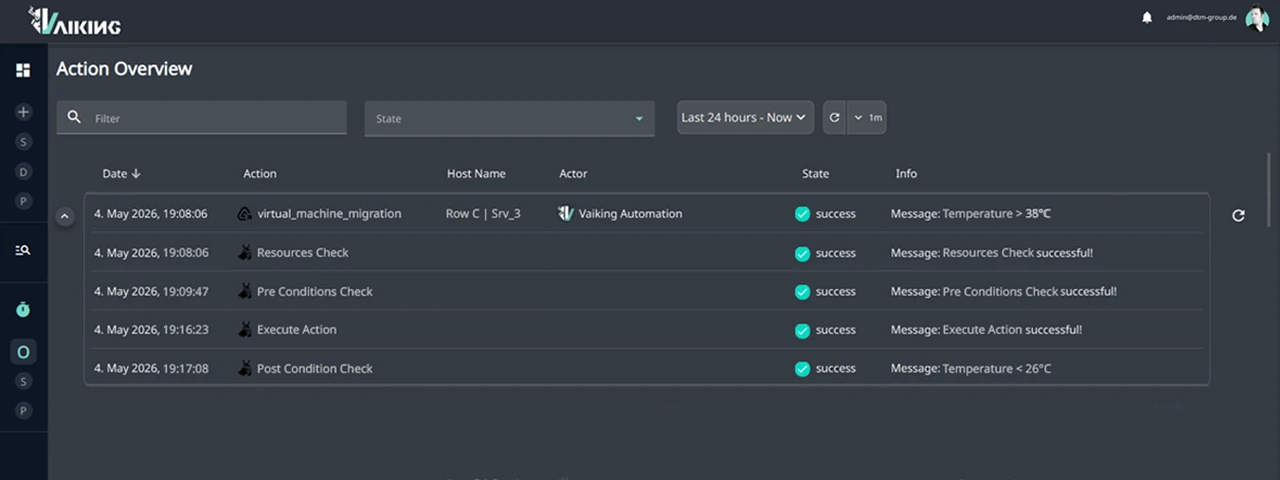
Rack-Reihe C, 38°C. Vaiking erkennt den Temperaturanstieg.
PRE: Kapazität auf benachbarten Hosts geprüft. Kein aktives Wartungsfenster. Ressourcen-Budget verfügbar. Vorbedingungen erfüllt.
EXEC: VM-Migration auf weniger belastete Hosts ausgeführt. Zeitstempel: 03:12 Uhr.
POST: Temperatur in Rack-Reihe C nach wenigen Minuten bei 26°C. Ziel-Zustand erreicht.
SLA unberührt. Vollständig protokolliert. Kein Alarm beim Bereitschaftsdienst.
AUTOMATISIERUNG BEGINNT NACH VALIDIERTEM MONITORING
Automatisierung setzt ein stabiles, validiertes Monitoring voraus. Das ist die Grundvoraussetzung für verlässliche Eingriffe.
Der erste Einstieg sind Prozesse, die bisher manuell, aber sauber dokumentiert waren: wiederkehrende Neustarts, bekannte Eskalationsketten, geplante Wartungsaufgaben. Schnelle Wins zuerst. Das sind keine Parallelprojekte. Das ist der nächste Schritt nach stabilem Monitoring.
Das Automatisierungs-Modul setzt den Vaiking Monitoring-Datenstrom voraus. Wer mit dem Monitoring beginnt, legt damit die Grundlage. Das Gespräch klärt, ob Ihr Setup den Reifegrad für den nächsten Schritt bereits hat.
SCHRITTWEISE AKTIVIERUNG. JEDE AKTION FREIGEGEBEN. BESTEHENDE PROZESSE BLEIBEN.
Freigabe pro Aktion, nicht pro Kategorie
Keine pauschalen Automatisierungsregeln. Jede Aktion wird einzeln konfiguriert und separat freigegeben. Was nicht explizit aktiviert ist, wird nicht ausgeführt.
Analysemodus als Startpunkt
Vaiking startet im Analysemodus: Daten lesen, korrelieren, Alarme ausgeben. Automatisierte Eingriffe werden erst aktiv, wenn Sie es konfigurieren und freigeben. Schrittweise Erweiterung, kein Systemwechsel.
Bestehende ITSM-Prozesse bleiben führend
Ticketing-Systeme, ITSM-Plattformen und Eskalationspfade werden nicht ersetzt. Das Automatisierungs-Modul ergänzt den Datenstrom und kann Tickets auslösen. Bestehende Prozesse laufen weiter.
Ausstieg ohne Umbau bestehender Systeme
Einführung und Abbestellung des Automatisierungs-Moduls sind ohne Datenverlust oder Systemumbau möglich. Das Monitoring-Modul läuft davon unabhängig weiter.
SIE WISSEN, WAS DAS SYSTEM KANN. JETZT KLÄREN WIR, WAS ES FÜR IHREN BETRIEB LEISTET.
Wir prüfen, welche manuellen Eingriffe in Ihrem Setup regelbasiert und sicher automatisiert werden können.